[23.05.01] 웹크롤링 라이브러리 (기사 스크랩, melon chart top100 수집)
# 크롤링의 원리
- 절차는 빅픽처에서 보면 아래와 같다.
1. 정보를 가져올 사이트를 불러온다.
2. 원하는 정보와 해당 정보의 위치를 찾는다.
3. 정보를 가져오게 하는 코드를 작성한다.
# Request - Success
# Request ?
# 브라우저 역할을 대신 해준다.

# Request - Failed
- 우리는 어떤 형태로든 인생에 있어서 거절당해본 경험이 있다.
- 마찬가지로 컴퓨터도 항상 우리가 원하는 응답과 결과를 주진 않는다.

# Beautifulsoup Library
- HTML 문서 내 데이터에 접근할 수 있게 변환해주는 Library
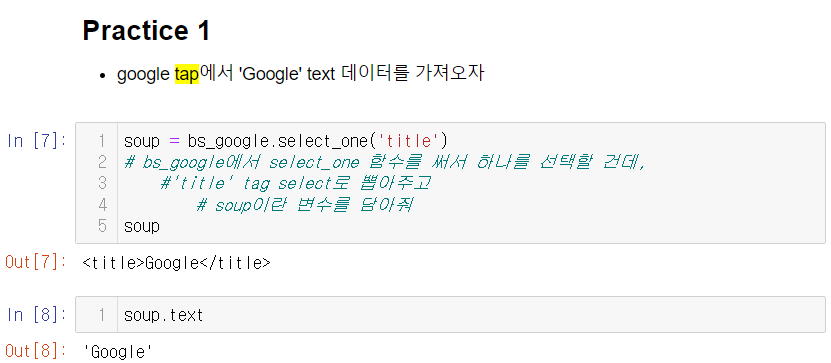
google tap에서 'Google' text 데이터를 가져오자
youtube에 접속해서 youtube의 타이틀을 tab에 저장하고, 그리고 텍스트 형식으로 가져와보세요


# NAVER Menu들에서 '메일' 텍스트를 추출

Beautifulsoup으로 객채화를 진행해줘야 함

f12 눌러서 개발자모드로 요소들 확인하기
CSS Selector는 어떤것이 있을까?
1. tag selector('태그이름') -> google, youtube 실습 때 사용
2. id selector(#)
3. class selector(.)-> 네이버 메일 실습 때 사용 / ** ('태그이름.클래스이름')
4. child selector(>)
5. parent selector(&)
6. adjustcent selector(+)
7. General Sibling (일반형제) selector(~)





NAVER NEWS 기사제목 가져오기
# 기억해주셔야 할 부분
# 우리는 같은 네이버 서비스를 이용하고 있지만, 컴퓨터 모름
# NAVER NEWS page 를 새로 요청 (res 다시 객체화)
# select, 혹은 select_one 함수로 태그의 위치를 저장
# 출력


기사'들'을 뽑아오기
- select 함수로
- for 문 (for loop) 이용해서 추출

개인 실습
1. 네이버 창 -> 원하는 키워드 검색
2. 뉴스 탭으로 이동
3. beautifulsoup으로 요소들을 뽑아보고
4. 그 중 맘에 드는 기사 하나를 추출
import requests as req
from bs4 import BeautifulSoup as bs1. 요청 (req) / 응답받기(res)
# https://search.naver.com/search.naver?sm=tab_hty.top&where=news&query=cj%EC%A0%9C%EC%9D%BC%EC%A0%9C%EB%8B%B9&oquery=%EB%9F%AC%EC%8B%9C%EC%95%84+%EC%9A%B0%ED%81%AC%EB%9D%BC%EC%9D%B4%EB%82%98+%EC%A0%84%EC%9F%81&tqi=iZ8Vvsp0Jy0ssCv%2B%2BDhsssssswV-433348
url_cj = 'https://search.naver.com/search.naver?sm=tab_hty.top&where=news&query=cj%EC%A0%9C%EC%9D%BC%EC%A0%9C%EB%8B%B9&oquery=%EB%9F%AC%EC%8B%9C%EC%95%84+%EC%9A%B0%ED%81%AC%EB%9D%BC%EC%9D%B4%EB%82%98+%EC%A0%84%EC%9F%81&tqi=iZ8Vvsp0Jy0ssCv%2B%2BDhsssssswV-433348'
# request 브라우저를 사용자가 켜는 것과 같다.
# 1. 요청(req) / 응답받기(res)
res_news_cj = req.get(url_cj)
res_news_cjres_news_cj.text2. beautifupsoup으로 객체화 시키기 ('lxml' 형태로 가져오기)
# 2. Beautifulsoup으로 객채화
soup_cj = bs(res_news_cj.text,'lxml')
soup_cj3. 기사 가져오기 .select('태그이름.클래스이름')
# 3. 기사 하나만 가져오기
article_cj = soup_cj.select('a.news_tit')
article_cj[0].text4. for, len 써서 기사 여러개 가져오기
# 4. 기사 여러개 가져오기
for i in range(len(article_cj)):
print(article_cj[i].text)
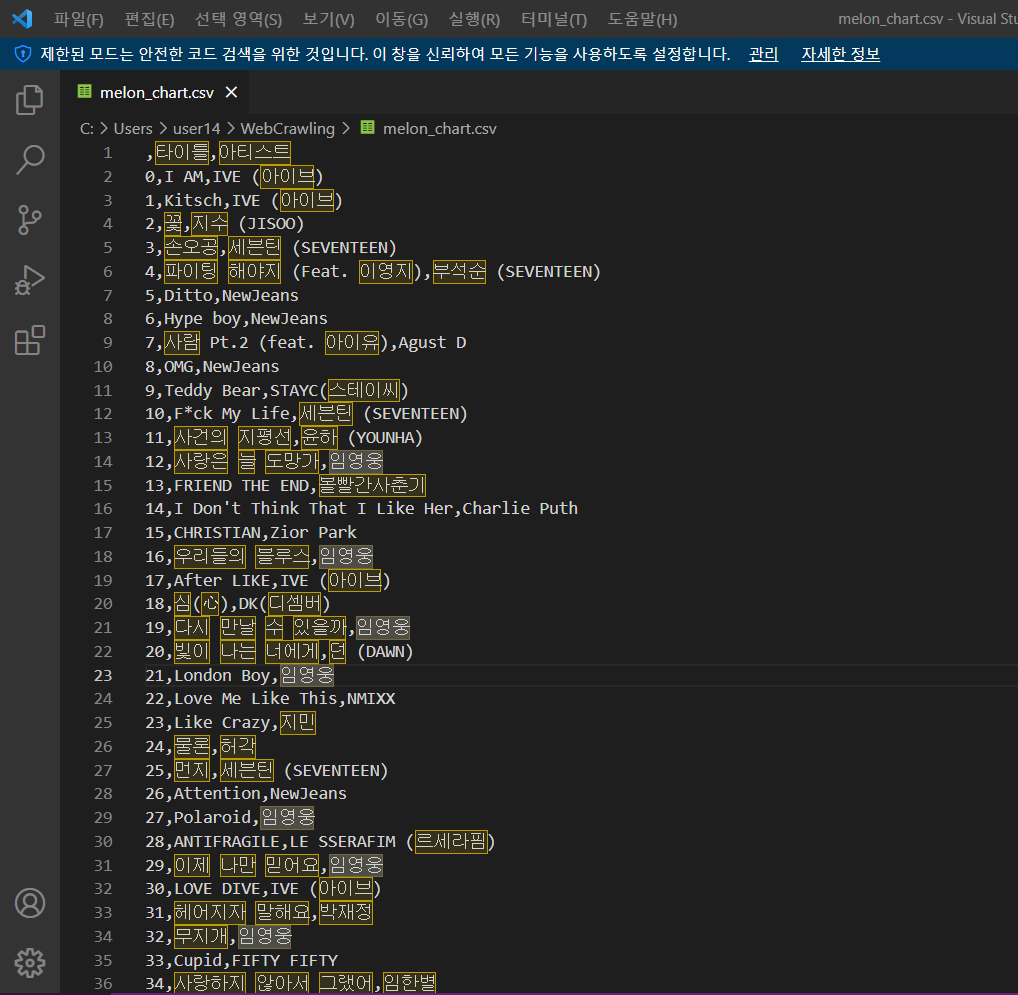
Melon Chart top 100수집 [타이틀 아티스트]
- 타이틀과, 아티스트 명을 beautifulsoup 사용해서 수집
- for loop 적용
- 마지막으로, 데이터를 pandas Library의 DataFrame에 집어넣기
- 특정 파일로 내보내기 (데이터 저장 파일을 내보내기)
# 라이브러리 로딩
import requests as req
from bs4 import BeautifulSoup as bs
import pandas as pd# https://www.melon.com/chart/
# 406 클라이언트의 요청이 문제
# 브라우저 대 브라우저가 아닌, 코드로 인식을 해서 접근을 멜론에서 막음
# head = {'User-Agent' : '주소'} 지정하기.
# headers = head
url_melon = 'https://www.melon.com/chart/'
head = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'}res_melon = req.get(url_melon, headers = head)
res_melonBeatifulSoup 객체화
soup = bs(res_melon.text, 'lxml')
soupCSS Selector
1. tag selector('tag 이름') -> google, youtube 실습 때 사용
2. id selector(#)
3. class selector(.)-> 네이버 메일 실습 때 사용 / * ('태그이름.클래스이름')
4. child selector (>)
5. parent selector (&)
6. adjustcent selector (+)
7. General Sibling (일반형제) selector (~)
# selector로 곡 제목 요소'들'을 뽑아보자!
titles = soup.select('div.ellipsis.rank01 > span > a')
titles[0].text# for loop
for i in range(len(titles)):
print(titles[i].text)I AM
Kitsch
꽃
손오공
파이팅 해야지 (Feat. 이영지)
Ditto
Hype boy
사람 Pt.2 (feat. 아이유)
OMG
사랑은 늘 도망가
F*ck My Life
Teddy Bear
FRIEND THE END
사건의 지평선
우리들의 블루스
I Don't Think That I Like Her
CHRISTIAN
다시 만날 수 있을까
London Boy
After LIKE
Polaroid
심(心)
이제 나만 믿어요
Like Crazy
먼지
무지개
빛이 나는 너에게
아버지
물론
Love Me Like This
Attention
ANTIFRAGILE
A bientot
LOVE DIVE
April shower
인생찬가
헤어지자 말해요
Cupid
사랑하지 않아서 그랬어
손이 참 곱던 그대
Fire
사랑해 진짜
I Don't Understand But I Luv U
NIGHT DANCER
연애편지
Dangerously
보금자리
사랑인가 봐
Dynamite
Heaven(2023)
사랑하기 싫어
Zero
밤이 무서워요 (Lonely Night)
Nostalgia
봄날
HOT
너의 모든 순간
Perfume
Candy
가질 수 없는 너
건물 사이에 피어난 장미 (Rose Blossom)
Butter
on the street (with J. Cole)
발걸음
Nxde
VIBE (feat. Jimin of BTS)
해요 (2022)
해금
That's Hilarious
너를 보는게 지친 하루에
Say I Love You
Monologue
Permission to Dance
STAY
Set Me Free Pt.2
Shut Down
새삥 (Prod. ZICO) (Feat. 호미들)
ELEVEN
나비무덤
KNOCK
취중고백
다시 사랑한다면
Pink Venom
그라데이션
TOMBOY
내가 아니라도
안녕이라고 말하지마
Cookie
FEARLESS
정이라고 하자 (Feat. 10CM)
그중에 그대를 만나
나의 마음에 (Seed)
Say My Name
다정히 내 이름을 부르면
그때 그 순간 그대로 (그그그)
오르트구름
빙글빙글 (Prod. R.Tee)
모든 날, 모든 순간 (Every day, Every Moment)
That’s Not How This Works (feat. Dan + Shay)
결국엔 너에게 닿아서# selector로 artists 요소'들'을 뽑아보자!
# 왜 103개가 뽑혔을까?
# 듀엣곡 때문, 한 곡 당 최소 2명의 아티스트
# 즉, 2개의 a tag가 존재
# 아이태그입 a tag 가 말썽이었네?
# 부모님 소환 -> 퉁
artists = soup.select('div.ellipsis.rank02')
artists[0].text
# 위 경우를 보니 아티스트가 중복되는 경우도 있었다.
# 개발자 모드 F12를 켜서 보니, 그 밑에 또 다른 태그가 있었다.
# 그러면, 어떻게 해야할까?len(artists)artists = soup.select('div.ellipsis.rank02 > span')
artists[0].text
# 크롤링은 결국 족보싸움이다.
# 내가 원하는 태그 내 데이터에 id, Class가 불확실하다면,
# 그 위에 부모태그, 혹은 조부모태그, 혹은 조상까지 타고 올라가야 할 수도 있다.# for loop
for i in range(len(artists)):
print(artists[i].text)IVE (아이브)
IVE (아이브)
지수 (JISOO)
세븐틴 (SEVENTEEN)
부석순 (SEVENTEEN)
NewJeans
NewJeans
Agust D
NewJeans
임영웅
세븐틴 (SEVENTEEN)
STAYC(스테이씨)
볼빨간사춘기
윤하 (YOUNHA)
임영웅
Charlie Puth
Zior Park
임영웅
임영웅
IVE (아이브)
임영웅
DK(디셈버)
임영웅
지민
세븐틴 (SEVENTEEN)
임영웅
던 (DAWN)
임영웅
허각
NMIXX
NewJeans
LE SSERAFIM (르세라핌)
임영웅
IVE (아이브)
세븐틴 (SEVENTEEN)
임영웅
박재정
FIFTY FIFTY
임한별
임영웅
세븐틴 (SEVENTEEN)
임영웅
세븐틴 (SEVENTEEN)
imase
임영웅
Charlie Puth
임영웅
멜로망스
방탄소년단
임재현
지아
NewJeans
주주 시크릿
우디 (Woody)
방탄소년단
세븐틴 (SEVENTEEN)
성시경
NCT 도재정
NCT DREAM
#안녕
H1-KEY (하이키)
방탄소년단
j-hope
J. Cole
DK(디셈버)
(여자)아이들
태양
#안녕
Agust D
Charlie Puth
송하예
우디 (Woody)
테이
방탄소년단
The Kid LAROI
Justin Bieber
지민
BLACKPINK
지코 (ZICO)
IVE (아이브)
포맨 (4MEN)
이채연
김민석 (멜로망스)
한동근
BLACKPINK
10CM
(여자)아이들
주호
V.O.S
NewJeans
LE SSERAFIM (르세라핌)
BIG Naughty (서동현)
김호중
태양
Say Yes!
경서예지
전건호
WSG워너비 (가야G)
윤하 (YOUNHA)
헤이즈 (Heize)
폴킴
Charlie Puth
WSG워너비 (가야G)수집한 타이틀, 아티스트 데이터를 for loop를 통해 리스트에 집어 넣자
# 자료형을 확인해보자
type(titles)
#bs4.element.ResultSet이네?
#리스트와 매우 유사하지만 엄연히 다른 객체
#but 우리는 python 기반 pandas library 를 사용해야 한다.
# 그럼, 빈 리스트 2개를 선언해서 for loop으로 순차적으로 담자bs4.element.ResultSet# 빈 리스트를 선언
titles_list = []
artists_list = []
for i in range(len(titles)):
titles_list.append(titles[i].text)
artists_list.append(artists[i].text)
print(titles[i].text, artists[i].text)
DataFrame
# 1. Dictionary 형태로 만들어 줘야합니다.
# Dictionary로 우선 선언해 줘야하는 이유 :
# 1. 각각의 행과 열에 대한 데이터를 쉽게 입력할 수 있다.
# 2. frame 내 데이터 타입을 일치시키기 쉽게 구성할 수 있다.
# 3. dictionary 로 먼저 저장을 해주면,
# 데이터 구조가 보존됩니다.
# Pandas DataFrame으로 변경할 때, 일관성이 유지됩니다.melon_dic = {'타이틀': titles_list, '아티스트' : artists_list}
melon_dicmelon_df = pd.DataFrame(melon_dic)
melon_df
# CSV 파일로 내보내기
# 항상 파일로 내보내는 습관이 필요하다
# 나중에 다시 다 돌려서, 다시 뽑아야하는 불상사가 빈번
melon_df.to_csv('C:/Users/user14/WebCrawling/melon_chart.csv', encoding = 'euc-kr')